结论在文章末尾,若要看结论,请直接拉到最后~
(p.s.开头叠个甲:文章结论是韶子通过《汉语方言大词典》中数据推出的(目前手头只有这部词典的数据),不代表韶子认同本文的方言分类方法。)
复旦大学许宝华教授和日本京都外国语大学的宫田一郎教授合作编纂了《汉语方言大词典》一书。词典中记载了中国 2113 个县或县级以上观测单元所使用的具体汉语方言[1]。中山大学的徐现祥教授将其整理成可了编辑的电子表格[2]。
《汉语方言大词典》等
词典及表格中记载的行政区划(绝大部分)是 1986 年的行政区划(但也有一些疏漏和错误之处,比如使用了更早的行政区划而没有使用当时最新的)。徐现祥教授将 1986 年的行政区划中《汉语方言大词典》没有列出的那些县也整理到了表格中,方言区使用空白占位。
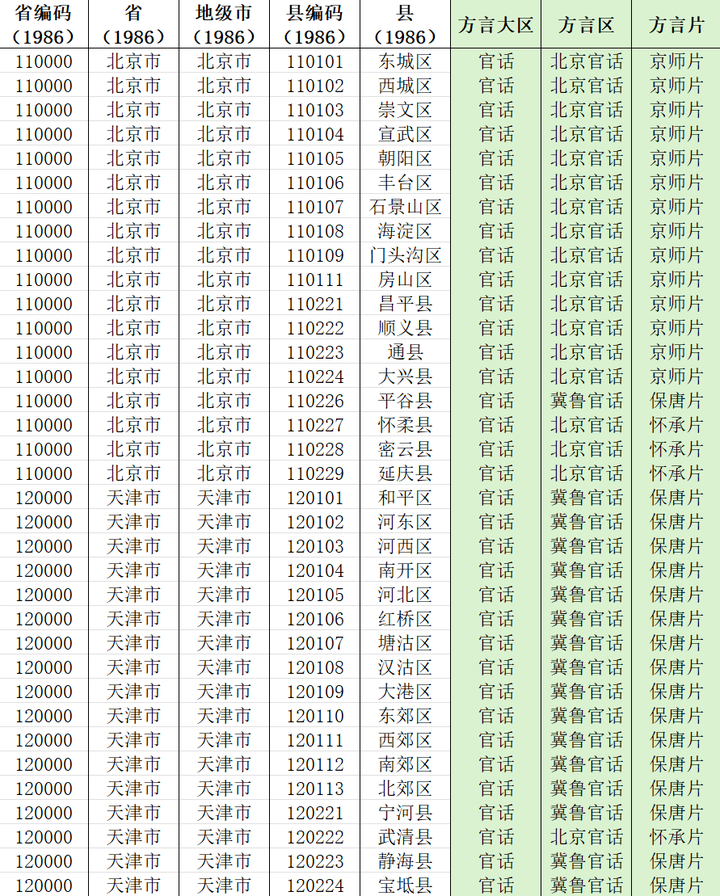
韶子根据《中国语言地图集 第 2 版 汉语方言卷》[3],将部分空缺的县的方言片区补充了上去。在补充的过程中,尽量使用《汉语方言大词典》原本的方言分类方法,并且不对原书记载的内容进行更改,以期数据内容格式尽量统一。
并且韶子还找到了一个收集并分析中华人民共和国县级以上行政区划代码自 1980 年至今的历史数据及新旧代码间的对应关系数据的项目:
yescallop/areacodes: 中华人民共和国县级以上历史行政区划代码及新旧代码对应关系数据集 (github.com)
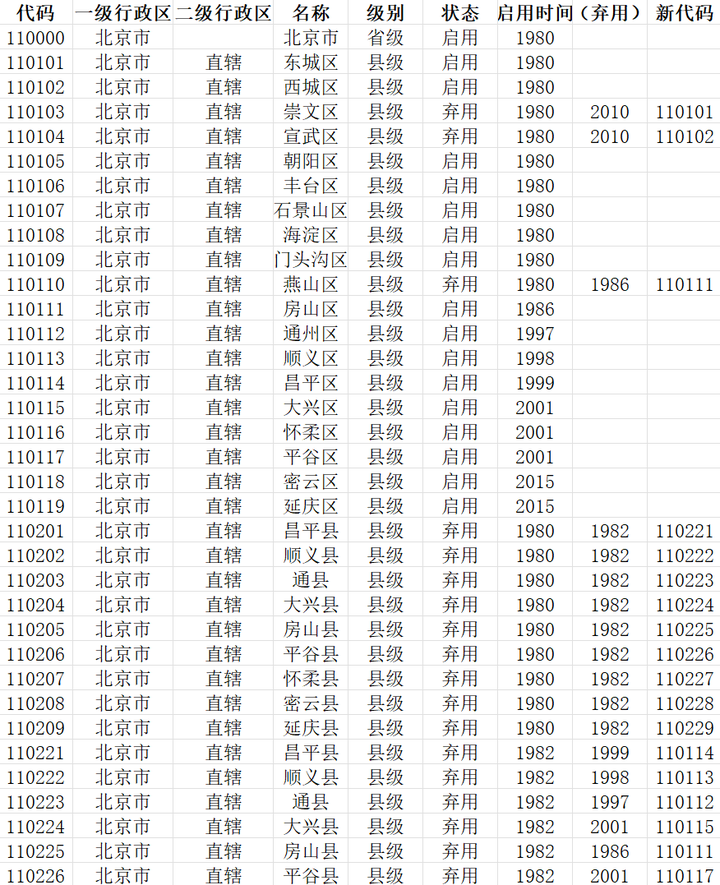
根据对照表,将 1986 年的行政区划编码自动转换至 2023 年的行政区划编码:
import pandas as pd
import re
codes_df = pd.read_csv(r"C:\Users\Nephelium\Desktop\python_projects\areacodes-master\result.csv")
codes_df['代码'] = codes_df['代码'].astype(str).str.strip()
def find_active_code(update_df, codes_df, original_code):
code = str(original_code).strip()
visited_codes = set()
while True:
if code in visited_codes:
print(f"循环检测: {original_code} -> {code}")
return code
visited_codes.add(code)
update_rows = update_df[update_df['县编码(1986)'] == code]
codes_rows = codes_df[codes_df['代码'] == code]
if codes_rows.empty:
print(f"未找到代码: {original_code} -> {code}")
print(f"当前代码 '{code}' 的类型: {type(code)}")
print(f"代码 '{code}' 是否在 '代码' 列中: {code in codes_df['代码'].values}")
return code
if len(codes_rows) > 1:
update_city = update_rows.iloc[0, 2] if not update_rows.empty else None
matching_rows = codes_rows[codes_rows.iloc[:, 2] == update_city]
if len(matching_rows) == 0:
print(f"代码 {code} 对应多行,且二级行政区不匹配:")
print(codes_rows)
else:
codes_rows = matching_rows
# 检查所有匹配的行
for _, row in codes_rows.iterrows():
status = row['状态']
if status in ['启用', '变更', '弃用']:
# 检查 '新代码' 是否为 NaN 或浮点数
if pd.isna(row['新代码']):
# print(f"代码 {code} 的新代码为空")
new_code = code # 如果新代码为空,保持原代码不变
else:
# 删除方括号及其中的内容
new_code_str = re.sub(r'\[.*?\]', '', str(row['新代码']))
new_codes = new_code_str.split(';')
new_code = new_codes[-1][-6:].strip()
if status == '启用' and pd.isna(row['新代码']):
return new_code
else:
code = new_code
break # 找到第一个需要更新的代码后就跳出循环
else:
print(f"未知状态 {status}: {original_code} -> {code}")
return code
# 如果所有行都检查完毕且没有返回,继续下一轮循环
# 读取需要更新的 CSV 文件
update_df = pd.read_csv(r"C:\Users\Nephelium\Desktop\python_projects\dialect diversity\中国各地区全国分省份地市州盟地县级城市区县方言分布数据集.csv")
# 定义一个函数来更新县代码
def update_county_code(code):
return find_active_code(update_df, codes_df, code)
# 应用函数到'县编码(1986)'列,并将结果存储在'县代码(2023)'列
update_df['县代码(2023)'] = update_df['县编码(1986)'].apply(update_county_code)
update_df.to_csv('updated_file.csv', index=False, encoding='utf-8-sig')
print("文件已更新并保存为 'updated_file.csv'")
但是该程序在转换上目前仍有一些小 bug,查询的时候若遇到一个编码在历史上有多个县 / 市使用过,则有可能转换为错误的编码。所以还需要人工核验一遍。转换后,用 Excel 的 TEXTJOIN 函数和 LEFT 函数可自动生成对应的市级编码和省级编码,然后通过 XLOOKUP 函数可将省市县名称补全。(这个表格放到文章开头的链接里啦)
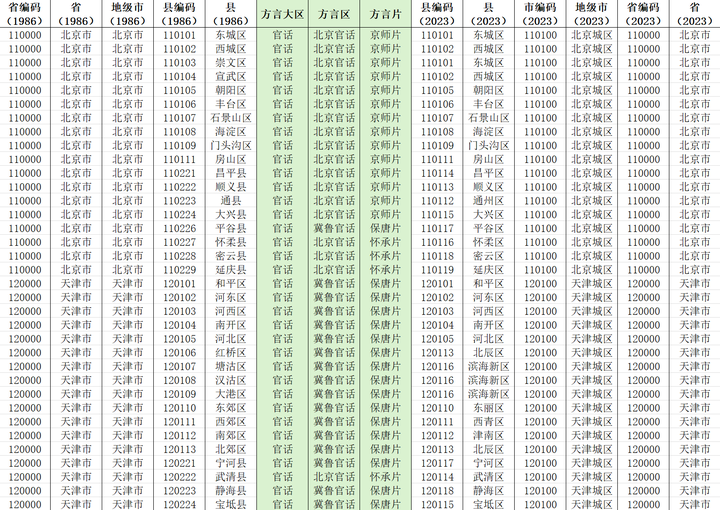
import pandas as pd
import numpy as np
# 读取数据
df = pd.read_csv(r'C:\Users\Nephelium\Desktop\python_projects\dialect diversity\中国各地区全国分省份地市州盟地县级城市区县方言分布数据集 2023.csv', sep=',')
# 创建一个包含省份、地级市名称和市编码的 DataFrame
pref_info = df[['省(2023)', '地级市(2023)', '市编码(2023)']].drop_duplicates()
# 统计每个地级市的非空方言片数量
dialect_count = df.groupby('地级市(2023)')['方言片'].apply(lambda x: x.dropna().nunique()).reset_index()
dialect_count.columns = ['地级市(2023)', '方言片数量']
# 合并方言片数量和地级市信息
result = pd.merge(pref_info, dialect_count, on='地级市(2023)', how='right')
# 重新排列列的顺序
result = result[['省(2023)', '地级市(2023)', '市编码(2023)', '方言片数量']]
# 检查是否有方言片数量为 0 的地级市
zero_dialects = result[result['方言片数量'] == 0]
if not zero_dialects.empty:
print("以下地级市的方言片数量为 0:")
print(zero_dialects)
print("\n")
# 保存方言片数量为 0 的地级市到 CSV
zero_dialects_path = r'C:\Users\Nephelium\Desktop\python_projects\dialect diversity\方言片数量为 0 的地级市.csv'
zero_dialects.to_csv(zero_dialects_path, index=False, encoding='utf-8-sig')
print(f"方言片数量为 0 的地级市已保存到: {zero_dialects_path}")
# 检查是否有空的方言片
empty_dialects = df[df['方言片'].isna() | (df['方言片'] == '')]
if not empty_dialects.empty:
print(f"共有 {len(empty_dialects)} 条记录的方言片为空")
print("空方言片记录示例:")
print(empty_dialects.head())
print("\n")
# 保存空方言片记录到 CSV
empty_dialects_path = r'C:\Users\Nephelium\Desktop\python_projects\dialect diversity\空方言片记录.csv'
empty_dialects.to_csv(empty_dialects_path, index=False, encoding='utf-8-sig')
print(f"空方言片记录已保存到: {empty_dialects_path}")
# 将结果保存为新的 CSV 文件
output_path = r'C:\Users\Nephelium\Desktop\python_projects\dialect diversity\地级市方言片数量统计.csv'
result.to_csv(output_path, index=False, encoding='utf-8-sig')
print(f"结果已保存到: {output_path}")
print(result)
然后,编写统计各个地级市方言多样性的脚本。运行后会生成统计好的表格。然后即可根据该表格统计每个地级市辖区内的方言数量了。省级也是类似的操作。
韶子还找到了ChinaAdminDivisonSHP项目。该项目提供了中国地图的矢量版。
GaryBikini/ChinaAdminDivisonSHP: 中国行政区划矢量图,ESRI Shapefile 格式,共四级:国家、省 / 直辖市、市、区 / 县。关键字:中国行政区划图;中国地图;中国行政区;中国行政区地图;行政区地图;行政区;行政区划;地图;矢量数据;矢量地理数据;省级;直辖市;市级;区 / 县级;行政区划图。 (github.com)
将 shp 文件中的属性和字段提取出来用于进一步的编辑。(刚刚使用 XLOOKUP 函数补全省市县名称用的即是县级行政区划的 shp 文件导出的表格)
import geopandas as gpd
import pandas as pd
# gdf = gpd.read_file(r"C:\Users\Nephelium\Desktop\个人图书馆\行政区划\ChinaAdminDivisonSHP-master\3. City\city.shp")
gdf = gpd.read_file(r"C:\Users\Nephelium\Desktop\个人图书馆\行政区划\ChinaAdminDivisonSHP-master\2. Province\province.shp")
gdf.drop('geometry', axis=1).to_csv('prov_output.csv', index=False, encoding='utf-8-sig')
print("CSV 文件已保存")
将刚刚查询到的结果添加至提取的 shp 属性表格中,生成新的 shp 文件:
import geopandas as gpd
import pandas as pd
gdf = gpd.read_file(r"C:\Users\Nephelium\Desktop\python_projects\dialect diversity\3. City\city.shp")
csv_data = pd.read_csv(r'C:\Users\Nephelium\Desktop\python_projects\dialect diversity\city_input.csv', encoding='utf-8-sig')
if 'numbers' not in csv_data.columns:
raise ValueError("CSV 文件中没有 'numbers' 列")
if len(gdf) != len(csv_data):
raise ValueError("Shapefile 和 CSV 文件的行数不匹配")
gdf['numbers'] = csv_data['numbers']
output_path = r"C:\Users\Nephelium\Desktop\python_projects\dialect diversity\3. City\city_updated.shp"
gdf.to_file(output_path, encoding='utf-8')
print("更新后的 Shapefile 已保存")
print(f"新添加的列:'numbers'")
print(f"总行数:{len(gdf)}")
使用 QGIS 加载这些 SHP 文件,即可看到按照 2023 年的行政区划统计的方言多样性地图:
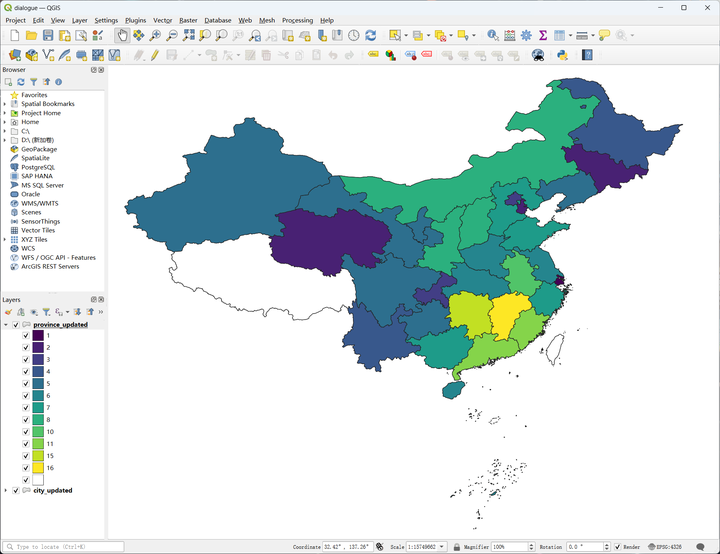
省,方言片列表
上海市,['太湖片']
云南省,"['昆贵片', '滇西片', '灌赤片', '黔北片']"
内蒙古自治区,"['张呼片', '大包片', '五台片', '朝峰片', '吉沈片', '哈阜片', '黑松片', '怀承片']"
北京市,"['京师片', '保唐片', '怀承片']"
吉林省,"['哈阜片', '吉沈片']"
四川省,"['成渝片', '灌赤片', '黔北片', '川西片', '秦陇片', '昆贵片']"
天津市,"['保唐片', '怀承片']"
宁夏回族自治区,"['银吴片', '银南片', '秦陇片', '陇中片', '关中片']"
安徽省,"['洪巢片', '宣州片', '信蚌片', '郑曹片', '蔡鲁片', '洛徐片', '休黟片', '绩歙片', '祁德片', '怀岳片']"
山东省,"['石济片', '沧惠片', '青州片', '登连片', '郑曹片', '蔡鲁片', '洛徐片']"
山西省,"['并州片', '五台片', '大包片', '上党片', '邯新片', '汾河片', '保唐片', '吕梁片']"
广东省,"['广府片', '粤台片', '粤北片', '勾漏片', '四邑片', '潮汕片', '高阳片', '吴化片', '雷州片', '惠州片', '粤中片']"
广西壮族自治区,"['邕浔片', '桂柳片', '广府片', '钦廉片', '桂南片', '娄邵片', '勾漏片']"
新疆维吾尔自治区,"['塔密片', '克石片', '南疆片', '石克片', '北疆片']"
江苏省,"['洪巢片', '宣州片', '太湖片', '洛徐片', '郑曹片', '泰如片']"
江西省,"['昌靖片', '抚广片', '鹰弋片', '宜浏片', '黄孝片', '鹰戈片', '湘南片', '于桂片', '宁龙片', '宜萍片', '铜鼓片', '处衢片', '祁德片', '休黟片', '吉茶片', '吉莲片']"
河北省,"['石济片', '保唐片', '邯新片', '张呼片', '怀承片', '沧惠片', '郑曹片']"
河南省,"['郑曹片', '洛徐片', '蔡鲁片', '邯新片', '汾河片', '信蚌片']"
浙江省,"['太湖片', '严州片', '瓯江片', '闽南区', '台州片', '婺州片', '处衢片']"
海南省,"['府城片', '文昌片', '万宁片', '儋州话', '崖县片', '昌感片']"
湖北省,"['武天片', '黄孝片', '大通片', '鄂北片', '成渝片', '常鹤片']"
湖南省,"['长益片', '宜浏片', '吉茶片', '耒资片', '娄邵片', '洞绥片', '大通片', '昌靖片', '常鹤片', '湘南片', '于桂片', '黔北片', '吉溆片', '岑江片', '成渝片']"
甘肃省,"['金城片', '河西片', '秦陇片', '陇中片', '关中片']"
福建省,"['侯官片', '泉漳片', '莆仙区', '闽中区', '汀州片', '大田片', '邵将区', '抚广片', '闽北区', '处衢片', '福宁片']"
西藏自治区,[]
贵州省,"['昆贵片', '黔北片', '灌赤片', '岑江片', '黔南片']"
辽宁省,"['吉沈片', '哈阜片', '登连片', '盖桓片', '朝峰片']"
陕西省,"['关中片', '秦陇片', '成渝片', '延长片', '志延片', '五台片', '大包片', '吕梁片']"
青海省,"['秦陇片', '陇中片']"
黑龙江省,"['哈阜片', '黑松片', '吉沈片', '登连片']"
台湾省,[]
香港特别行政区,[]
澳门特别行政区,[]
省(2023) 方言片数量
江西省 16
湖南省 15
广东省 11
福建省 11
安徽省 10
陕西省 8
山西省 8
内蒙古自治区 8
山东省 7
河北省 7
浙江省 7
广西壮族自治区 7
江苏省 6
河南省 6
海南省 6
湖北省 6
宁夏回族自治区 5
贵州省 5
甘肃省 5
四川省 5
新疆维吾尔自治区 5
辽宁省 5
黑龙江省 4
云南省 4
重庆市 3
北京市 3
天津市 2
吉林省 2
青海省 2
上海市 1
西藏自治区 0
香港特别行政区 0
澳门特别行政区 0
台湾省 0
可以看出,根据《汉语方言大词典》中的方言分类方法,方言数量最多的省是江西省,拥有 16 个方言片;其次是湖南省,拥有 15 个方言片,再次是广东省和福建省,拥有 11 个方言片。香港特别行政区、澳门特别行政区和台湾省的数据书中并未给出,西藏自治区缺乏方言调查数据,因此数量暂列为 0。
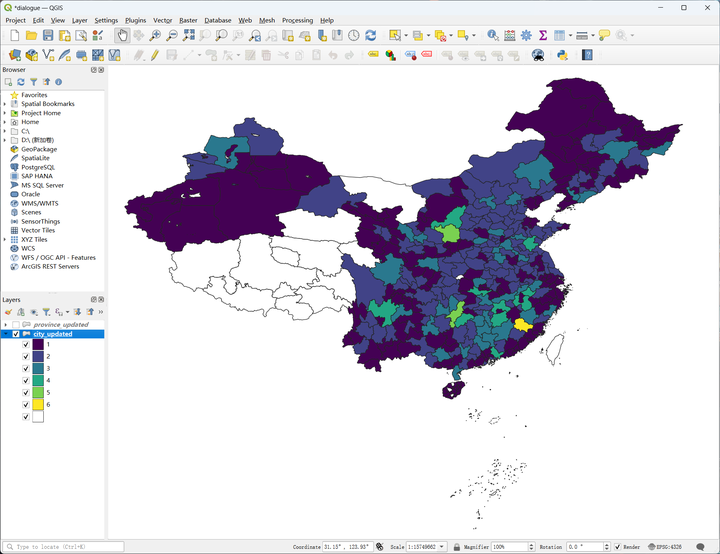
方言数量最多的地级市是福建省三明市,拥有 6 个方言片;然后是陕西省延安市、湖南省怀化市,拥有 5 个方言片;江西省上饶市 吉安市 宜春市、山东省临沂市、四川省凉山彝族自治州、广东省惠州市、陕西省榆林市湖北省荆州市、湖南省邵阳市和安徽省黄山市,拥有 4 个方言片。
《汉语方言大词典》一书成书年代较早,尽管方言数据调查已经十分完备,但仍有部分地区的数据缺失,并且书中方言分区方法与当前主流分区方法仍有差异。因此,该统计结果有争议也是正常的。
韶子准备暑假的时候将《中国语言地图集 第 2 版 汉语方言卷》和《中国语言地图集 第 2 版 少数民族语言卷》统计为电子版 Excel 表格,放到网上开源(如果不咕的话),然后根据《中国语言地图集》的数据重新制作两张方言多样性的地图。
到时候再更新叭 hhh
文章如有疏漏或错误,欢迎大家指出~
 微信扫一扫
微信扫一扫