因爲在當今電腦都使用的 Unicode(統一碼、萬國碼)裏,處理到「中日韓統一表意文字」的收錄時,應用到兩個對立的原則:表意文字認同原則(Han Unification Rule,又稱表意文字統合原則)與原規格分離原則(Source Separation Rule,又稱原字集分離原則)。
認同原則與原規格分離原則
東亞各國字形多有微妙的差異。如「房」字的第一筆,韓國傳統漢字字形、臺灣敎育標準字形作撇;香港敎育參考字形、中國大陸規範作點;日本標準作橫。又如「次」字的左旁,韓國採用傳統字形,首筆爲橫,次筆爲挑,即「二」字作左旁偏旁時的末橫讓右變挑之寫法;臺灣敎育字形作兩橫,即「二」字而且末橫不讓右變挑;大陸、日本、香港等則作「冫」(俗稱兩點水)。這種程度的差異,理想上是整併作一個字爲佳。否則,要是凡異體字都收進不同碼位裏,Unicode 收錄的漢字就會過於臃腫,用戶搜尋時也會因異體問題而找不到想要的結果。
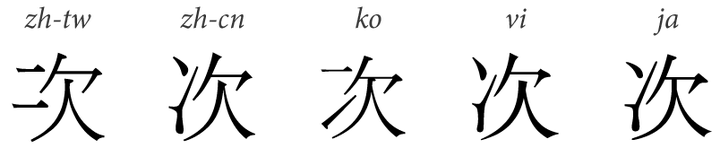
然而,從之前各種受挫之文字整併計劃的經驗得知,整合字集與現行通用字集(Big5 或國標碼)等無法一一對應,是推行整合字集的最大阻礙。例如,日本的 JIS(日本產業規格,Japanese Industrial Standards)編碼裏,同時收錄了「剣」字與「劍」字,原本 JIS 文件裏這兩個字可以並存。若採用整合字集後,它們會變成同一個字,就會造成使用上的困擾。而且,如果將多個不同地區字形合併,會影響閱讀者,令使用者不習慣並非以往所見字形;更有可能引致閱讀者因習慣而書寫不屬於自己地區的字形(或地區性的異體字)。
於是,表意文字認同原則與原規格分離原則就應運而生。
在表意文字認同原則下,Unicode「只對字(Character),而不對字形(Glyph)」編碼,會把同一字的不同字形(即異體字)合併。好像上述的「次」字,在 Unicode 裏會整併成一個碼。又例如不同地區而有不同寫法的部首,如「⻌(中國大陸規範、日本新字體)、⻍(港臺舊字形、韓國、日本舊字體)、⻎(臺灣敎育字形)」、「礻(首筆是頓點,中國大陸規範、臺灣敎育字形)、⺭(首筆是直點,日本新字體)、⺬(日本舊字體、韓國、港臺舊字形)」、「爫(中國大陸、港臺新字形)、⺥(舊字形)」等,都會合併編碼。這些部首的寫法差異就會交由字型處理。比如說,使用依中國大陸漢字標準《印刷通用漢字字形表》的字體下(如中易宋體、微軟雅黑體)便會出現「⻌、爫」;使用臺灣敎育標準字形(如微軟正黑體或新版細明體,但非舊版細明體[1])就會出現「⻎、爫」等字形。這大大解決了因地區而異之部首寫法。
至於原規格分離原則是指,在上述所列出之各種來源文本裏,若有任何字集同時收了兩種以上的文字字形,則在 Unicode 中日韓統一表意文字中,也同時收錄這些字。這樣一來,現行的各種原有字集與 Unicode 漢字可以一一對應。比如「房」字,各地字集都沒有分別編碼,就只編進一個碼位,部首第一筆的寫法交由字型處理。然而,「戶」、「户」、「戸」這三個字,在一些地區標準裏是分別編碼的,Unicode 則以三個碼位來分別收錄它們。 上述的「劍」與「剣」也一樣,要分別收錄到不同的碼位。
基於上述運作,Unicode 能大幅減少收錄漢字字數,同時讓地區編碼過渡至 Unicode 時,字集裏的字元不會有流失。但是,原規格分離原則破壞了 Unicode「只對字,而不對字形」編碼之原則,使某些漢字獲得兩個或多個編碼,亦遭受不少批評。
後來的一些重複漢字會使用「兼容區」提供暫存編碼,可以通過歸一化(normalization)步驟移除。比如維基百科,在編輯者按下「發佈更改」後,會把編輯區域裏的兼容區字元自動替換成非兼容區字元,換言之編輯者無法使用兼容區字元。一般的漢字輸入法,以及多數漢字字型,也不支援兼容區字元。用戶若要使用放在兼容區裏的字形,可能要花上額外的操作,甚至仍不得要領,無法選用。

另外,原規格分離原則只適用於最初 Unified Repertoire and Ordering(URO)的 20,902 字,換言之,由「擴展區 A」開始就不再適用。原因是個別地區提交了不少僅有十分輕微差異的字樣,比如臺灣《異體字字典》裏的各種異體,要求 Unicode 分別編碼。然而,那些字樣所立足的地區編碼,並非該地區的通用編碼,例如是「中文標準交換碼」(臺灣實際通行的編碼是 Big5 碼)。若 Unicode 全面採納,將會令 Unicode 對異體字的處理更混亂。最終,Unicode 決定自「擴展區 A」起就不再使用原規格分離原則。
今天,異體字選擇器(Variation Sequence)以及 Adobe 常用的 CID 字型等技術,已容許在一個 Unicode 編碼裏收錄和調用兩個或多個漢字字樣,原規格分離原則在今天已成爲過時技術的副產品。
起源不同原則
留意的是,可以整併的字只限異體字。如果有些漢字,它的音、義根本不一樣,是兩個不相同的字,即使它們外形相近,寫法差異比另一些整併的字少,但仍不能合併。這規則稱爲起源不同原則(Noncognate Rule)。
擧例說:「土」和「士」雖然形似,卻是兩個不同的字,我們不可以整併它們。(然而,日本、韓國、大陸、香港等地的「寺」字,與臺灣敎育字形的「寺」字,兩者頂部分別是「土」和「士」,但它們音義全同,是同一字的異體,於是就能夠整併。)
其他起源不同的例子還有「胄」和「冑」,「柿」和「杮」,「汨」和「汩」,「陝」與「陜」等。 這些字都不可以整併。
學界批評
中文文字學學界對 Unicode 的原規格分離原則有不少批評,尤其是它令同一個異體部件時而分離,時而合併,在日常使用層面引伸了許多問題。擧例說,「青」和「靑」、「淸」和「清」都在正常區域中作分離編碼,獲得兩個碼位;「晴」、「靖」、「精」雖也獲兩個碼位,但其中一個是在兼容區中,日常難以應用;「請」、「情」、「蜻」、「靜」更只有一個碼位。或例如,「直」、「植」、「埴」、「殖」、「置」的末筆無論是橫還是豎橫(豎折),都被整併作相同的碼位,可是「値」和「值」卻分離作兩個碼位。Unicode 的做法,沒有把含有相同異體部件的字全都合併,也沒有把它們全都分離,結果經常導致字形不一致,或者使用者無法選擇他希望使用的字形。
其他漢字使用地區也有類似聲音。例如「戋」和「㦮」兩個偏旁,前者爲「戔」的中國大陸簡化漢字,後者爲「戔」的日本略字,在「残」和「⿰歹㦮」、「浅」和「⿰氵㦮」、「践」和「⿰⻊㦮」等組合裏,Unicode 就整併起來。可是碰到「栈」和「桟」,卻不統合,分別安排到 U+6808 與 U+685F 兩個碼位中。這種情況遭日本學者指爲 Unicode 自相矛盾(參見:安岡孝一:《Unicodeの矛盾》)。
在下也寫過一篇《Unicode 摧殘正體字》,批評此問題。可以參閱:
說文:unicode 摧殘正體字 [刻石錄]
事實上,由於在「中日韓統一表意文字」的不同區域裏,Unicode 本身也使用了不一致的併分尺度,因此,早期的異體字時常獲分配正常碼位,後來常常只有兼容區的暫存編碼,再後來則不時被直接整併並交由異體字選擇器處理。若不修正或更改早期的編碼,類似的問題將會持續存在。
 微信扫一扫
微信扫一扫