谢邀…的确是个值得一说的题目,HIV 病毒的复制也是个比较复杂的过程。我不知道之前几位抓着个 typo 不放在嘲讽什么…
HIV 等逆转录病毒形成的 DNA 有没有启动子?有。
整合进基因组的 HIV-DNA 总是有自己独立的启动子和增强子的,因此才能够保证每次整合进人类染色体,都能源源不断的生产新的 HIV ssRNA,并包装成具有侵染性的病毒。
问题在于 HIV 包括两个拷贝的 ssRNA 基因组。这个 ssRNA 是线性的,不是一个环。所有的线性核酸的复制 / 转录 / 逆转录,都面临一个同样的问题——每次都会变短一点:
1)DNA -> RNA,转录产物丢失启动子和终止子的序列。(P.S. “启动子的密码子”是什么鬼?)
2)DNA/RNA -> DNA 合成的天然引物是 RNA,在复制后被降解了,这段序列也就丢失了。
其实解决的方法很简单。如果丢失的序列是重复的,本来就有 2 或>2 个拷贝,那么就可以在丢失之后重新补齐。
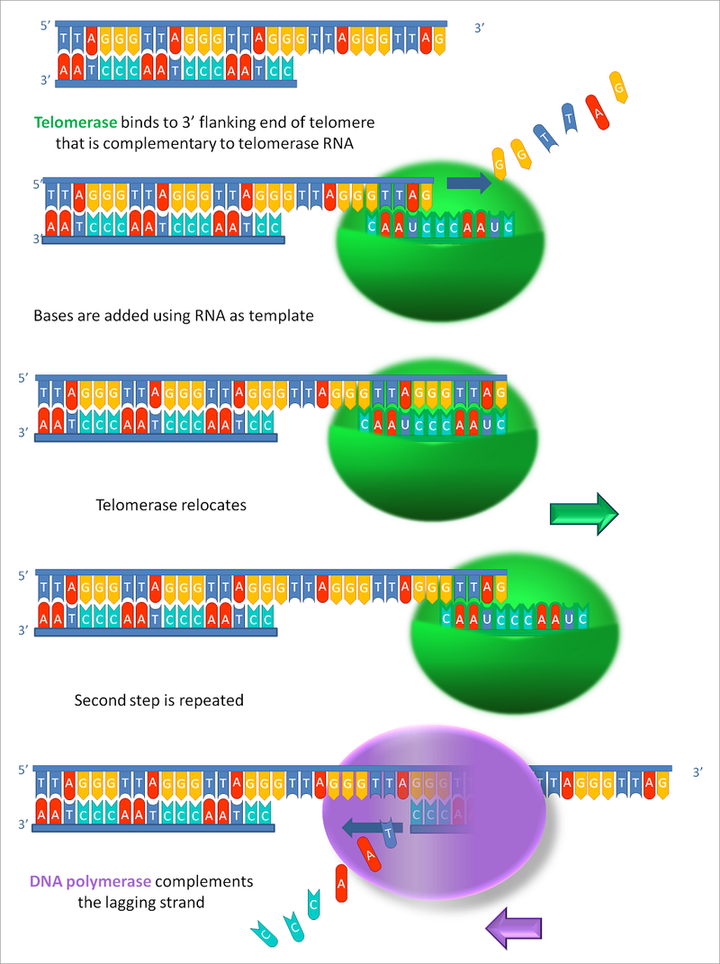
先举一个简单的、你可能比较熟悉的例子,真核生物的染色体 DNA(比如人),就是在线性 DNA 的两端加上重复序列端粒。当细胞需要把端粒延长的时候,端粒酶(Telemerase)就可以端粒酶 RNA(TERC)为模板,合成延伸端粒。而由于 TERC 的基因是在染色体内部,不会在染色体复制过程中丢失的。
而在 HIV 等逆转录病毒中,在基因组的末端各有一个长末端重复序列(Long terminal repeats,LTRs)。
HIV-DNA 转录成 ssRNA 时,两端的 LTRs,会各丢失一部分,转录起始所需的增强子和启动子序列(5’end U3)和转录终止所需的终止子序列(3’end U5)。但是由于两个 LTRs 的方向结构是相同的,都是 U3-R-U5,因此转录本的结构是:R-U5- 一堆基因 -U3-R。因此在逆转录 RNA -> DNA 的过程中,就可以通过对重复序列 R 的识别,将原本丢失的 U5 和 U3 补齐。
具体的机制要比端粒的延伸更为复杂,这有一张比较清楚的流程图,我就不翻译了:

(图片来源 wikipedia)
LTR 区域包括整个 U3-R-U5,介导大多数的调控过程,包括增强子、启动子、转录起始位点、终止子、PolyA 加尾信号。U5 序列会被整合酶 integrase 识别,将整段 dsDNA 嵌入宿主基因组。
题主的问题,起始只要了解了 HIV 的复制过程,困惑就迎刃而解,答案是一目了然的。
我个人觉得有趣的内容在于重复序列的利用是核酸扩增中的一个非常普适的技巧。无论是在天然的基因组复制过程中,还是日常实验中人工片段的合成。甚至在环形 DNA 的滚环复制当中,你也可以看到类似的机制。
 微信扫一扫
微信扫一扫