谢邀~这个项目其实做了挺久,从 6 月份开始筹划,中间差点没坚持下去,好在所有人齐心协力才最终完成。感谢各位帮助~
简单说下思路,其实就是常见的 RL+ 预训练,用视觉方案来代替指令读取(否则就成作弊了)当然正因如此,识别模块比读指令要多出很多问题,举几个例子
- 虚幻五的画面比较奇怪,导致模型经常识别到其他物体上
- CNN 不够深,有些招式判定的错误率高
- 锁定 BOSS 后如何处理一些导致锁定丢失的快速位移招式
等等。而这些我们都尝试了大量的方法去解决(前期我们是在只狼和法环上跑的验证)
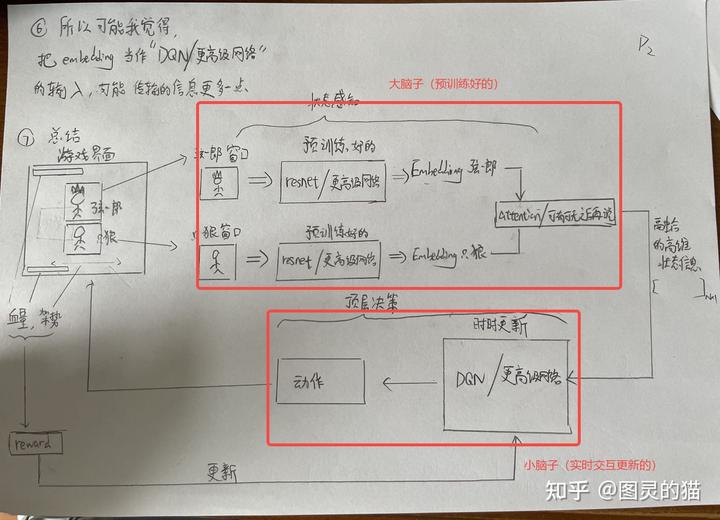
比如,猴在着火的时候血条会有火焰特效,导致血量识别不准确,我们就用 canny 边缘检测,检测血条框的边缘,选取所有行中的最“边缘”的像素点中的最大值,作为血条。

这些细节优化还有很多,因为视频时长关系我们只放了最核心的几点。
很多人说强化学习打游戏是外挂,但其实我觉得强化学习区别于其他监督学习、半监督学习最大的地方在于——他是一种可行性的探索方案。很多时候尝试某一种方法的代价是巨大的,我们不可能人工去遍历所有的可能性,甚至有些思路我们人工一时之间也无法完全想到。但是如果我们能对问题的场景进行仿真建模,我们就可以先通过强化学习广泛探索所有的可能性。
比如:如果我们把打只狼 / 黑神话的掉血的 reward 提高,让模型更关注到丢失血量,我们就会看到主角因为怕犯错误一直防御;又或者我们增加一些额外的动作操作,我们就可以看到模型选择其他的战斗思路(比如我们训练的只狼里面,只狼更喜欢跳跃躲避 boss 攻击,然后趁 boss 攻击的空挡反向打 boss,这个思路其实和大多数人的思路不一样)

强化学习的优势不是在于打赢 boss 与否(当然他有能力打赢很多 boss),他更强大的地方在于我们能人为控制条件,然后轻松通过这些条件看到未来的结果是怎样的。这个能力就让我们有机会,在限定的条件下(不是简单更改游戏数值,而是探索可行的策略),能以非常非常小的代价,尝试并看到无限多种的可能和结果。这个结果(或者也可以称为策略)是对我们在这个环境下有非常大的指导意义的。有可能网络学习的不是特别好,不能像人一样操作特别精准,但是他相当于提供了一种可行性的点子。这个点子或许以后可以交由更强的监督学习模型进行实现,但是强化学习把探索过程的代价降到了很低,我们其实根据强化学习的可以做更深层的原理分析和策略的选择。
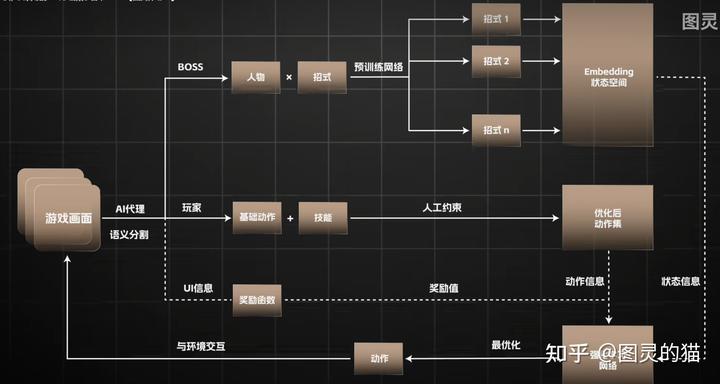
其实作为一个完全模仿人类大脑去打魂类游戏的项目,我们能接触到的只有图像,而并不能从内存中获得有关 boss 的状态、位置等的信息。人脑首先需要对图像进行分割,理解出血条、体力、敌人、可用道具等概念,再从敌人这一对象中分割出躯干和武器的组合后理解出各种招式,以及在合适的时机闪避和攻击。
但是在当下理解一张图里到底有什么对于 AI 来说,依然是一件难事。我们取静止的一帧画面来说,人类能从中获取出 boss 与玩家的距离,面对角度,使用的招式。而对于一个处理图像的 ai,除非动用 GPT4o 这种级别的大模型,想要完全理解我们只能将这些每个目标都设置对应的识别算法,识别之后,才能将这些信息作为状态置入强化学习的 boss 状态空间中。

而在这个项目中,我们将图像提取出必要的敌我血量以及其他数值信息后卷积作为强化学习的状态空间,agent 可能并没完全理解出到底发生了什么,但是能够明白在什么情况下做出哪些动作可以得到奖励,就已经能够后达到一般魂游萌新的水平,可见强化学习的潜力。将图像处理的这一部分进一步处理,将能显著提升 ai 玩家的性能。
考虑到效果和表现力,我们其实也加了少量的人工规则约束,比如蓄力重棍的时机,理论上这些规则是可以被学习到的,但确实这个项目比较赶,发售之后我们希望是 2 周内可以做出来,所以迭代的时间没有预期那么长,后续我们会继续优化,用模型代替规则。
此外我们还试了一些 Openpose 之类的姿态识别,但只能对人形怪有较好的表现,一旦妖怪的样子比较抽象,准确率就非常低。这个我们还在尝试优化。关于加点,因为前期就那么些灵光点,点不出什么流派,默认加的是根基和劈棍的前几招,包括识破。等后面技能点多了,可以考虑让 AI 多加一些做摸索,说不定能搞点新活。
PS.为了跑图我们也单独加了一套基于大模型的交互逻辑,用的是比较成熟的 Cradle 方案(感谢 BAAI 提供的帮助)进 BOSS 战前会判定并切换到战斗模组
https://github.com/BAAI-Agents/Cradle
最后,踏上取经路,比抵达灵山更重要,这句话也送给所有做科研、探索技术的各位共勉
 微信扫一扫
微信扫一扫