(甚至本來不抱破譯希望的,但意外地成功了 233
【順帶推一下前篇:破譯了一段有趣的亂碼 ww
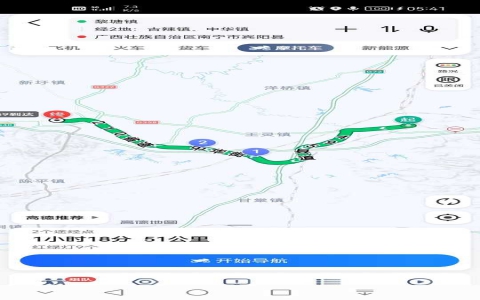
看有人轉了這麼個圖:

一開始討論,有人在猜是不是打字的人沒看屏幕,還有人猜是不是用諧音寫的別的語 233
但果然它還是更像某種軟硬件問題導致排印時出現的亂碼。
初分析
這回是一個完全沒有頭緒的亂碼。
首先排除 UTF-8 的嫌疑。因為 UTF-8 編碼的長度,和其他常見漢字編碼(也包括 UTF-16)都不一樣。而這張圖的排版卻很勻稱,並沒有明顯地歪掉,所以亂碼和原文應該字數一致(或頂多相差一個字左右)。
那麼是不是 UTF-16(BE 或 LE)跟 GBK 間的問題呢?試驗了一下發現不是這樣,因為這三者之間,無論怎樣轉換,都會含有不合法編碼或 Unicode 未賦字符的碼位或特殊字符。
這段文字出現在近期本地製作的標語裡,也不可能涉及 Big5、Shift-JIS 等其他地區的舊軟件編碼。
除了這些以外,我能想到的(而且實際見過的),就只剩下「電腦字型的字圖發生錯位」這種情況了:常見的電腦字型,由於包含的字符通常只是 Unicode 的很小的字集且對應編碼不盡連續,於是其包含的各個字的圖形(字圖,glyph)一般會在內部先以某種編號排列,然後再提供一個 Unicode 碼→字圖編號的表(一般是
cmap
表),用於揀出正確的字圖來。
但假如這張圖在排印時,對方程序(由於 bug 或者字型用了不常見的格式)搞混了不同的編號,或者是程序內部先緩存了文本的字圖編號,但字型檔卻由於某些原因被換成了別的,其字圖的排列與原字型不一致,就會揀出不正確的字圖來呈現。我之前實際遇上該問題,就是系統熱更新了使用中的字型,而運行中的程序重新加載了更新後的字型,卻用了更新前版本的字圖編號,就會出現這樣的現象。
不過,如果真的是這樣的話,能不能破譯原文,就不再是個能說得準的事了……因為字型中的字圖排列,理論上講是可以完全任意的,不管發生什麼都是有可能的。如果想要破譯的話,只能寄希望於兩套字型有相同且有規律的字圖排列順序(比如是按 Unicode 升序),且收字範圍基本一致了……
嘗試破譯嘗試一
這時,參與討論的另一個人也提出了這種可能,並且指出可以嘗試給文本每個字的 Unicode 碼加上個偏移量,窮舉可能的偏移量並篩選出裡面大部分字都是常用字的(比如 GB 2312 範圍內,或者再嚴些,它的一級字範圍內),再人工挑出通順的。
於是很快寫了段程序試驗了下。結果是——完全沒有通順的。。。看來恐怕並不是每個字都有相同的偏移量,這下就難辦了,因為可能性一下子大了好幾個量級。。。
嘗試二
於是……只好利用一點腦洞,來硬猜一下了!注意到裡面的「晃」和「皖」,按康熙字典部首分別是「日部」「白部」,而 Unicode 漢字基本區的字正是按康熙字典部首加筆畫數排列的,同部且筆畫數相近的字會排得較近。於是猜想這倆字分別是「是」和「的」。看一下 Unicode 碼的話:
- 「是」是 U+662F,「晃」是 U+6643,亂碼比原碼往後偏了 20。
- 「的」是 U+7684,「皖」是 U+7696,亂碼比原碼往後偏了 18。
這兩個差值都不大,且很接近!於是再次寫了個程序來試驗,以偏移量 +19 為中心,把鄰近編碼的字都列出來看看能不能從中挑出通順的文本來:
24 贘鍒昫仿丏百甘呷 宁兜昫聙巙百甘呷
23 贙鍓昬伀丐癿甙呸 宂兝昬聚巚癿甙呸
22 贚鍔昭企丑皀甚呹 它兞昭聛巛皀甚呹
21 贛鍕昮伂丒皁甛呺 宄兟昮聜巜皁甛呺
20 贜鍖是伃专皂甜呻 宅兠是聝川皂甜呻
19 贝鍗昰伄且皃甝呼 宆兡昰聞州皃甝呼
18 贞鍘昱伅丕的甞命 宇兢昱聟巟的甞命
17 负鍙昲伆世皅生呾 守兣昲聠巠皅生呾
16 贠鍚昳伇丗皆甠呿 安兤昳聡巡皆甠呿
15 贡鍛昴伈丘皇甡咀 宊入昴聢巢皇甡咀
14 财鍜昵伉丙皈產咁 宋兦昵聣巣皈產咁雖然眼花繚亂,但似乎可以從中挑出對應「田咏」的大概是「生命」,偏移量分別是 +17 和 +18。但其他的就看不太出了。
而如果想要再擴大範圍的話,眼睛就要更花了……這時想到,要不擴大範圍的同時再篩選一下,只顯示 GB 2312 範圍內的字如何呢:
38 昝 丁 孳 昝聋
37 仲 职
36 星仳七 孵 星聍巍
35 映 甍 兑映 甍
34 仵
33 件 甏 甏
32 价万 兔
31 丈 甑 孺兕 聒 甑
30 春 三癸 呱 兖春 癸 呱
29 上 甓呲 联 甓呲
28 昧任下 味 孽 昧 味
27 昨 丌登 昨 登
26 份不 呵 党 呵
25 与白 呶 宀 聘 白 呶
24 仿 百甘呷 宁兜 百甘呷
23 丐 甙呸 聚 甙呸
22 昭企丑 甚 它 昭 巛 甚
21 宄
20 是 专皂甜呻 宅 是 川皂甜呻
19 贝 且 呼 州 呼
18 贞 昱 丕的 命 宇兢昱 的 命
17 负 世 生 守 生
16 皆 安 巡皆
15 贡 昴 丘皇 咀 入昴 巢皇 咀
14 财 昵伉丙皈 宋 昵 皈
13 责 昶伊业 咂 完 昶 咂
12 贤 丛 全 工
11 败 东皋甥咄 左皋甥咄
10 账 伍丝 宏 巧
9 货 伎丞 咆 八 巨 咆
8 质 伏 皎用 公 聩巩皎用
7 贩 昼伐 甩 六昼聪 甩
6 贪 休 宓兮 巫
5 贫 显 丢皑甫 显 皑甫
4 贬 甬咋 宕兰 甬咋
3 购 两皓甭和 共 差皓甭和
2 贮 晁 严 宗 晁 巯
1 贯 甯咎 官关 甯咎
0 贰鍪晃众丧皖田咏 宙兴晃聱己皖田咏再次觀察,可以注意到對應「众丧」「宙兴」的,有可能是「企业」「安全」,偏移分別是 +22、+13、+16、+12。再大膽一點的話,還可以猜想下對應「聱己」的會不會是「职工」(偏移 +37 和 +12)。
這樣的話,目前初步的破譯結果是「??是企业的生命 安全是职工的生命」,已經是很常見的標語了~
然而,在試圖這樣猜開頭兩個字「贰鍪」的原文時,還是發現了意外:「鍪」字(U+936A)往前數好幾十碼都還沒見着常用字,甚至往前數一百個碼,也只有一個 GB 2312 範圍內的字「錾」(U+933E),偏移 +44。如果再要擴大範圍的話,可能性恐怕還是會多得多。。。
嘗試三
整理了下思路,突然想到,按 Unicode 碼來偏移的話,偏移量固然浮動很大,但實際上這個偏移應當是發生在字型的「收字範圍」內。所以如果在偏移編碼時,跳過不在 GB 2312 的字,那麼偏移量的浮動會不會小得多了呢?
於是先稍微驗證一下想法:在上面列出的僅含 GB 2313 字的表中,從亂碼字上方開始往上數(不含自身),但只數列出的字,看看會數出幾個:
- 從「晃」上方數到「是」:晁显昼昶昵昴昱是,8 個字
- 從「皖」上方數到「的」:皓皑皎皋皈皇皆的,8 個字
- 從「聱」上方數到「职」:聪聩聚聘联聒聍职,8 個字
試了三個字結果都是數出 8 個字,樣本裡甚至沒出現浮動!所以如果把亂碼字全都這樣往上數 8 個字,會是什麼結果呢?
於是重新寫了程序,把偏移改為只計 GB 2312 範圍內的字,統一往前偏移 8 個字。於是得到的結果是:
质量是企业的生命 安全是职工的生命居然一次就得到了通順的標語!
這樣的話,破譯就可以宣告成功了~
還原案發現場
原文本來是「质量是企业的生命 安全是职工的生命」,字型用的是一款收字範圍是 GB 2312 的。可是在排印時,字型的字圖編號被程序搞錯了,全都往後偏移了 8。於是每個字都變成了「按 Unicode 碼往後數第八個 GB 2312 範圍內的字」,就變成了「贰鍪晃众丧皖田咏 宙兴晃聱己皖田咏」。
 微信扫一扫
微信扫一扫